.svg)


Amazon Kinesis is a real-time data streaming service that allows users to collect, process, and analyze data from various sources. Apache Iceberg is an open-source table format for large-scale data lakes that provides efficient data management capabilities. Both Amazon Kinesis and Apache Iceberg are tools used for managing and analyzing large volumes of data, but they differ in their specific functionalities - Kinesis focuses on real-time data streaming, while Iceberg is more geared towards structured data management in data lakes.
Amazon Kinesis overview
Amazon Kinesis is a real-time data streaming service provided by Amazon Web Services (AWS). It is designed to collect, process, and analyze large streams of data in real-time, allowing users to gain insights quickly and make informed decisions based on up-to-date information.
The primary functions of Amazon Kinesis include data ingestion, processing, and analysis. It can handle large volumes of data from various sources, such as website clickstreams, IoT devices, and social media feeds, and process this data in real-time to enable real-time analytics, machine learning, and other applications.
Amazon Kinesis is typically deployed in scenarios where organizations need to process and analyze large streams of data in real-time, such as monitoring website traffic, analyzing sensor data from IoT devices, or processing log data for operational insights. It can be integrated with other AWS services, such as Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service, to build end-to-end data processing pipelines.
Apache Iceberg overview
Apache Iceberg is an open source table format for large-scale data processing that offers features like time travel, schema evolution, and data isolation. It provides a way to manage tables in a way that is efficient and scalable, making it easier to work with large datasets in a data lake or cloud storage environment.
Apache Iceberg is typically deployed in data lake environments where there is a need to manage large amounts of data efficiently. It can be used with popular data processing frameworks like Apache Spark and Presto, allowing users to easily query and analyze data stored in Iceberg tables. Iceberg tables are designed to be highly performant and reliable, making them a popular choice for organizations looking to streamline their data management processes.
Create an Amazon Kinesis source connector
To create a Source in the Decodable web app, navigate to the Connections page.
- On the Connections page, click the "New Connection" button in the upper right corner.
- Select the type (source or sink) and the external system you want to connect to from the list of available connectors.
- Enter the connectivity configuration and credentials in the dialog that opens and click "Next." The following behavior depends on whether the connector supports connecting to multiple streams or not.
If the chosen connector supports writing to or reading from multiple streams:
- A dialog appears from which you can configure the mappings between external resources and Decodable streams.
- Select which resources should be mapped by the connection by checking the corresponding "Sync" checkboxes, and which sinks their data should be sent to.
- Click "Next," choose a name in the following dialog window, and click "Create" or "Create and start".
More details are available in the Decodable documentation.

Create an Apache Iceberg sink connector
To create a Source in the Decodable web app, navigate to the Connections page.
- On the Connections page, click the "New Connection" button in the upper right corner.
- Select the type (source or sink) and the external system you want to connect to from the list of available connectors.
- Enter the connectivity configuration and credentials in the dialog that opens and click "Next." The following behavior depends on whether the connector supports connecting to multiple streams or not.
If the chosen connector supports writing to or reading from multiple streams:
- A dialog appears from which you can configure the mappings between external resources and Decodable streams.
- Select which resources should be mapped by the connection by checking the corresponding "Sync" checkboxes, and which sinks their data should be sent to.
- Click "Next," choose a name in the following dialog window, and click "Create" or "Create and start.
More details are available in the Decodable documentation.
Processing data in real-time with pipelines
A pipeline is a set of data processing instructions written in SQL or expressed as an Apache Flink job. Pipelines can perform a range of processing including simple filtering and column selection, joins for data enrichment, time-based aggregations, and even pattern detection. When you create a pipeline, you define what data to process, how to process it, and where to send that data to in either a SQL query or a JVM-based programming language of your choosing such as Java or Scala. Any data transformation that the Decodable platform performs happens in a pipeline. To configure Decodable to transform streaming data, you can insert a pipeline between streams. As we saw when creating a Snowflake connector above, pipelines aren’t required simply to move or replicate data in real-time.
Replicating data from systems like Amazon Kinesis to Apache Iceberg in real-time allows you to make application and service data available for powerful analytics with up to date data. It’s equally simple to cleanse data in flight so it’s useful as soon as it lands. In addition to reducing latency to data availability, this frees up data warehouse resources to focus on critical analytics, ML, and AI use cases.
Create a pipeline between Amazon Kinesis and Apache Iceberg streams
As an example, you can use a SQL query to cleanse the Amazon Kinesis to meet specific compliance requirements or other business needs when it lands in Apache Iceberg. Perform the following steps:
- Create a new Pipeline.
- Select the stream from Amazon Kinesis as the input stream and click Next.
- Write a SQL statement to transform the data. Use the form: <span class="inline-code">insert into <output> select … from <input></span>. Click "Next".
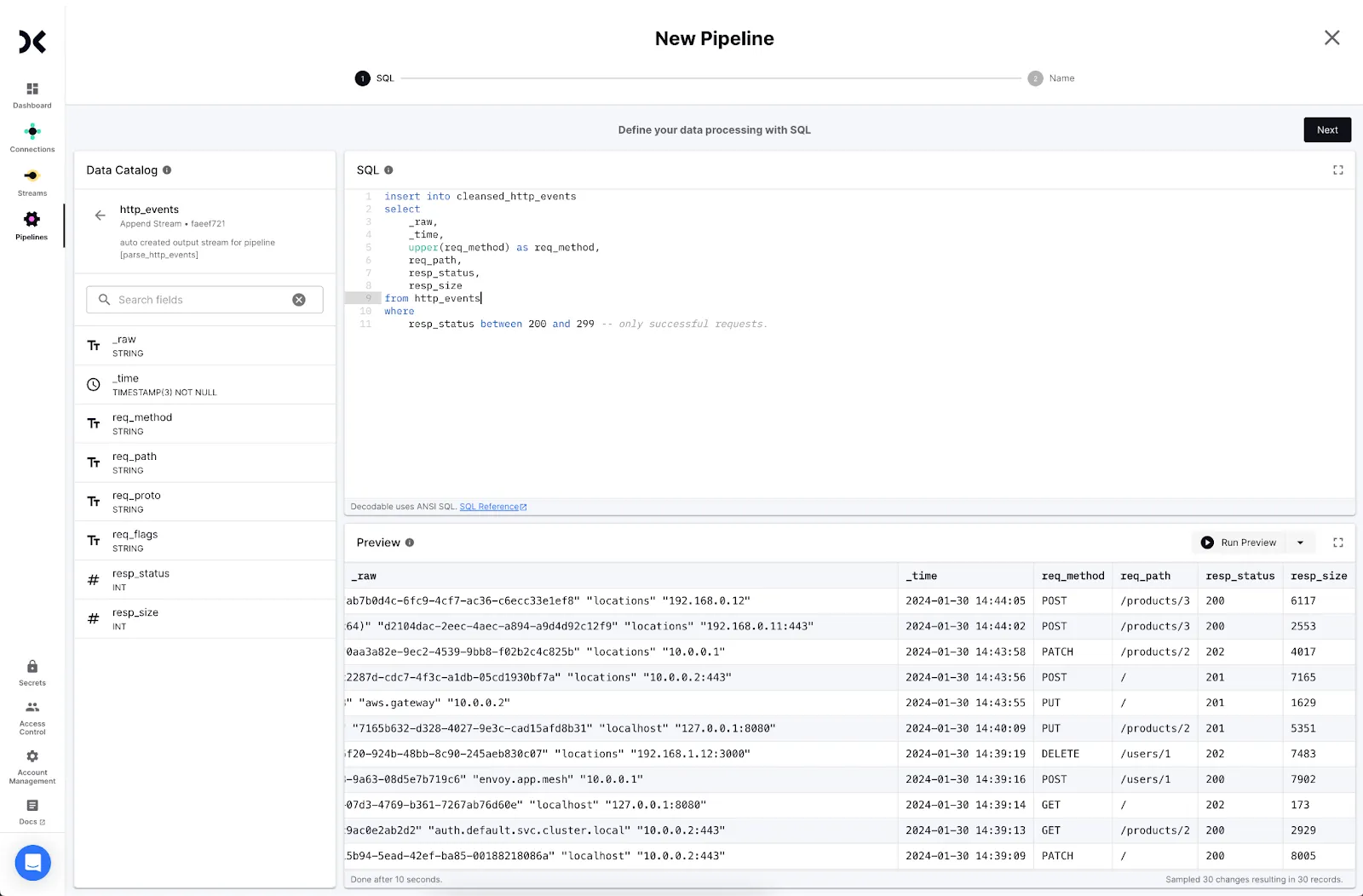
- Decodable will create a new stream for the cleansed data. Click Create and Next to proceed.
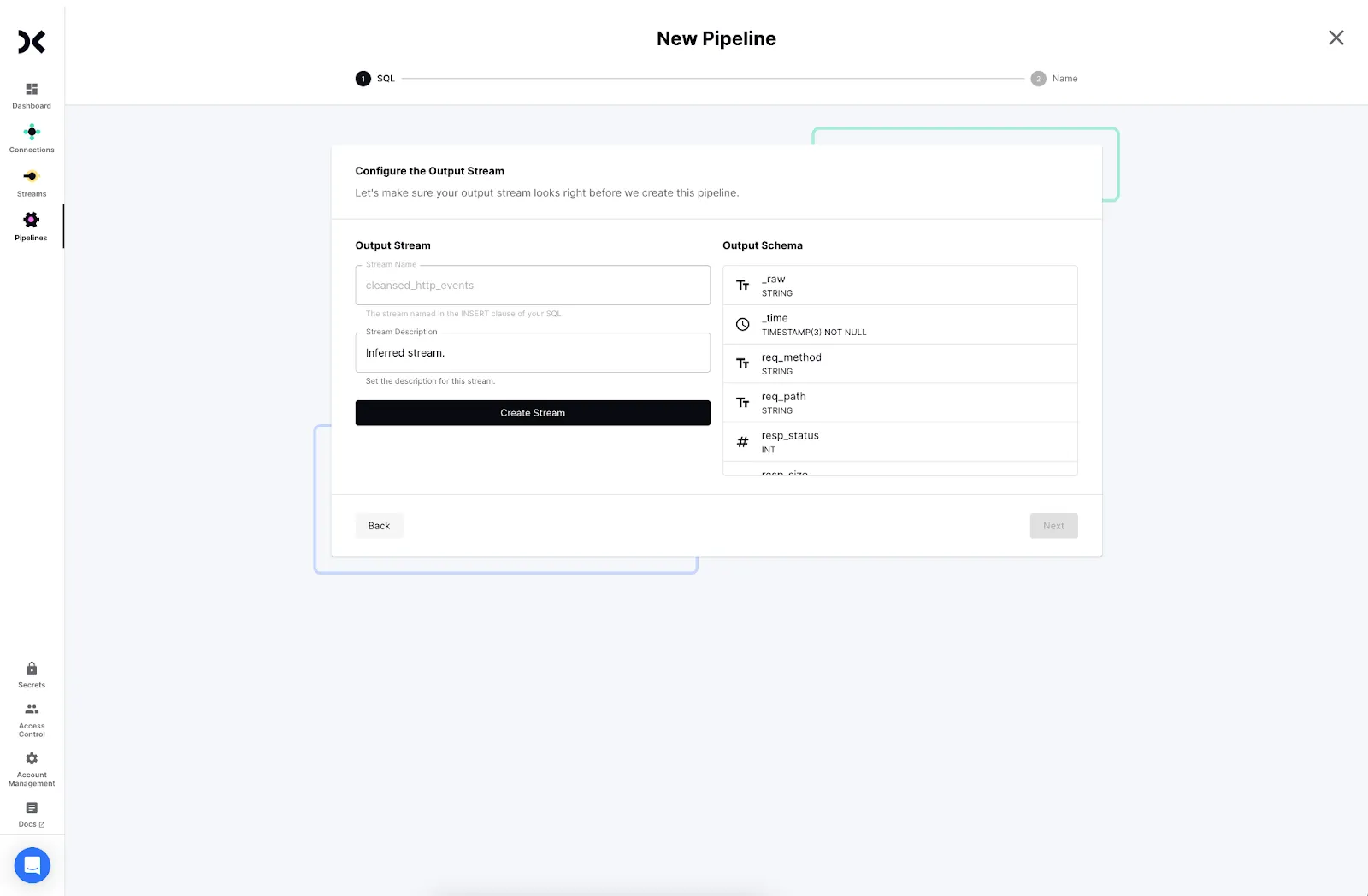
- Provide a name and description for your pipeline and click Next.
- Start the pipeline to begin processing data.
The new output stream from the pipeline can be written to Apache Iceberg instead of the original stream. You’re now streaming transformed data into Apache Iceberg from Amazon Kinesis in real-time.
Learn more about Decodable, a single platform for real-time ETL/ELT and stream processing.

